Introduction
This project began as a search for classification problems to tackle. I wanted to put my classification algorithm skills to the test, but wasn’t sure what data to use for this. Luckily, after digging around on the internet for a while, I came across the UC Irvine Machine Learning Data Repository. This repository has loads of datasets and even has a feature, "Default Task", that you can toggle in order to find the common machine learning task that would be applied to a given dataset. When looking through the Classification datasets I found a dataset regarding drug use that looked interesting. The dataset was originally collected by Elaine Fehrman, Vincent Egan, and Evgeny M. Mirkes in 2015.
This dataset provides 1885 data rows, each of which represents a person. Each person has a set of demographic and personality traits alongside a set of drug use responses. Data features included things like age, ethnicity, education level, country, extraversion score, openness to new experiences score, etc… The dataset looks at 17 common drugs (including chocolate??) and how recently someone has used each of the drugs. I decided to make drug use a binary outcome by grouping no usage ever and usage over a decade ago into "non user" and all other outcomes into "user", meaning that the person has used the drug within the last decade.
At this point I decided I would use Logistic Regression to predict whether or not a person was a user of each of the 17 drugs given in the dataset. This model information could help to determine which types of people are more susceptible to certain types of drug use given their personality type and demographic traits. This information could then be used to give treatment and assistance to those who require it.
ETL
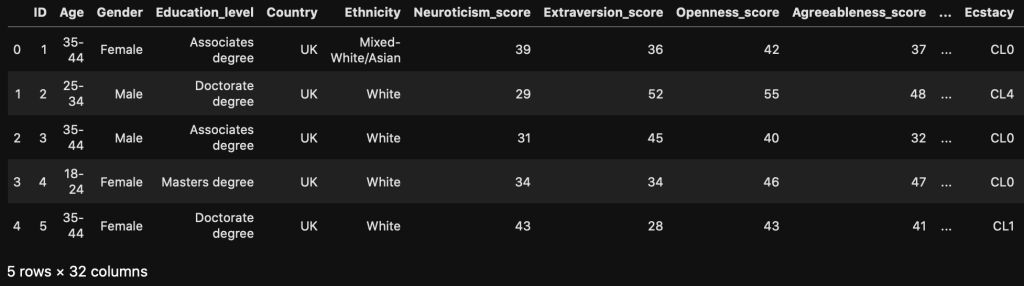
After importing the necessary libraries and loading in the dataset into a Pandas DataFrame, the raw data looks like this:

You can see that the data comes in a very weird format, but luckily there are descriptions on the data webpage. Using these descriptions, I transformed the data into a more coherent DataFrame.
Dummy Variables and Checks for Multicollinearity
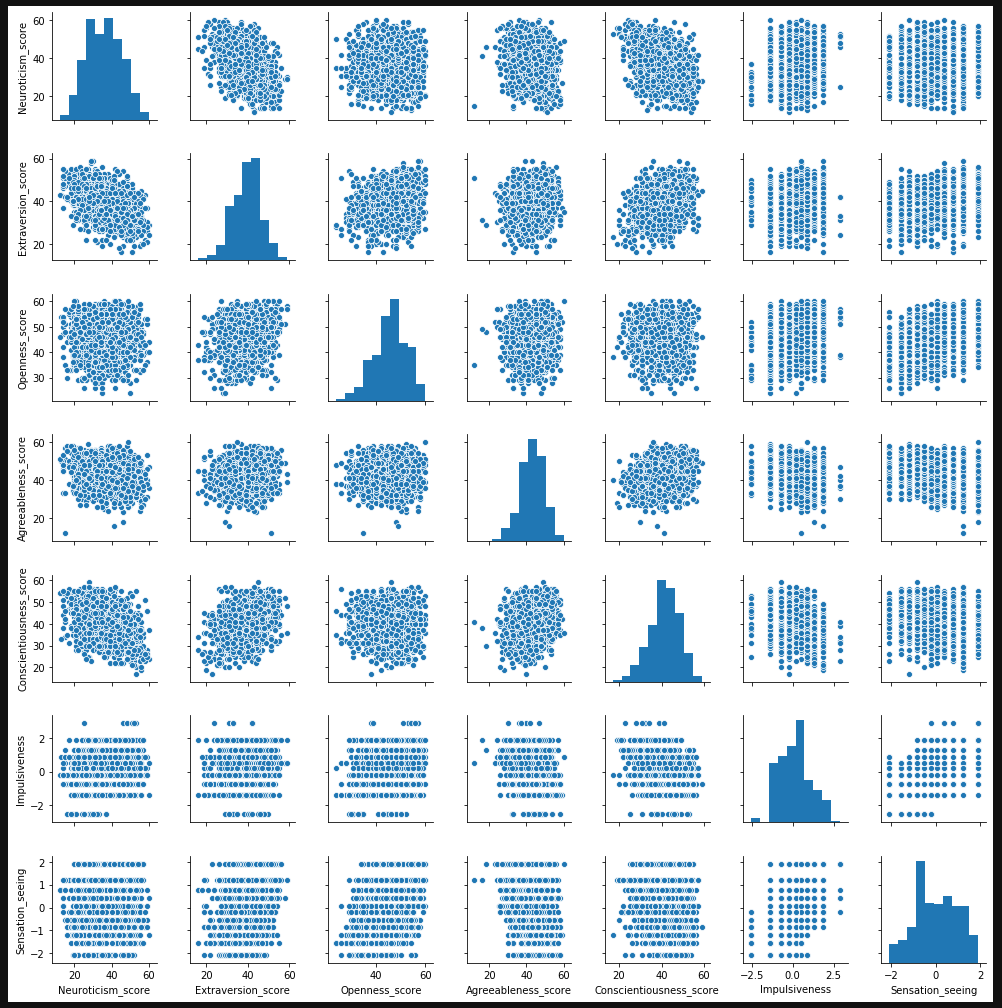
After getting the data into a useful format, I needed to deal with my categorical variables. I fit dummy variables to all of them and made sure to drop one of the resulting columns. I also needed to check if any of my numeric features had multicollinearity. As you can see in the seaborn pairplot below, the only two metrics that appear to have any multicollinearity are neuroticism and extraversion, but the correlation level is below .75, so I kept both scores in the DataFrame.
DataFrame Splitting
After a little more data manipulation (changing the column order), I needed to create separate DataFrames for each drug. I decided to store each of these in a dictionary, with each key being a name for the drug DataFrame and the value being the corresponding DataFrame. This was accomplished with the chunk of code below:

Note: The above portion of the code with df.iloc[:, :34] isolates the portion of the DataFrame corresponding to the features. After column 34 are the binary drug use columns.
Helper Functions for Model Fitting
First things first, I need to import the proper libraries and functions for all the tools I’ll need for my Logistic Regression process.
A quick note on the scikitplot library. This library has many awesome functions for calculating metrics and plotting them in one step. You’ll see a use of this for confusion matrices later on.
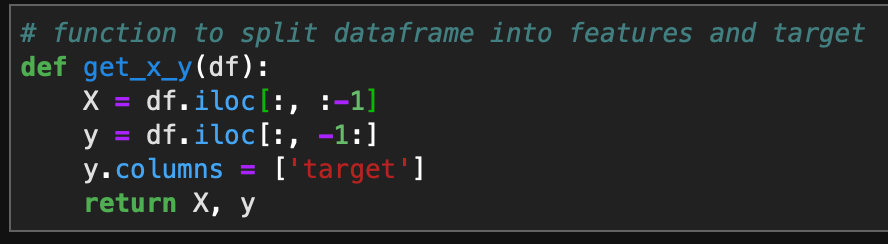
In order to loop through my new dictionary and fit a Logistic Regression model to each DataFrame, I needed to define a few helper functions. The first function will split the DataFrame into the features and the target, X and y respectively.
The next helper function will perform standard scaling on my numeric features after I have performed a train/test split on my data.

An additional helper function I wrote performs SMOTE on the datasets. Many of the drug user datasets are very unbalanced, so in order to train my model on a balanced dataset, I need to use SMOTE to synthetically create training data points for my minority class. This function is created below.

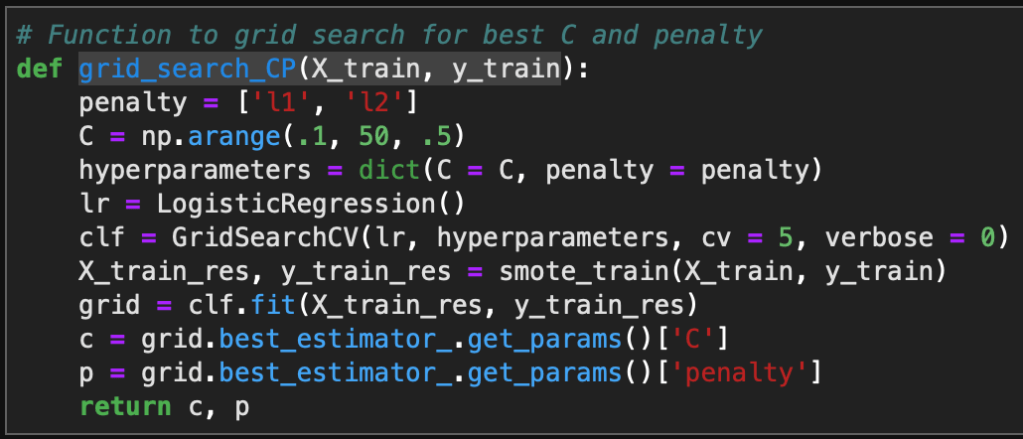
Another useful step in Logistic Regression is using a grid search for the best performing hyperparameters C and Penalty type. These control regularization of the models and this function will output the optimized hyperparameters for each drug use model.
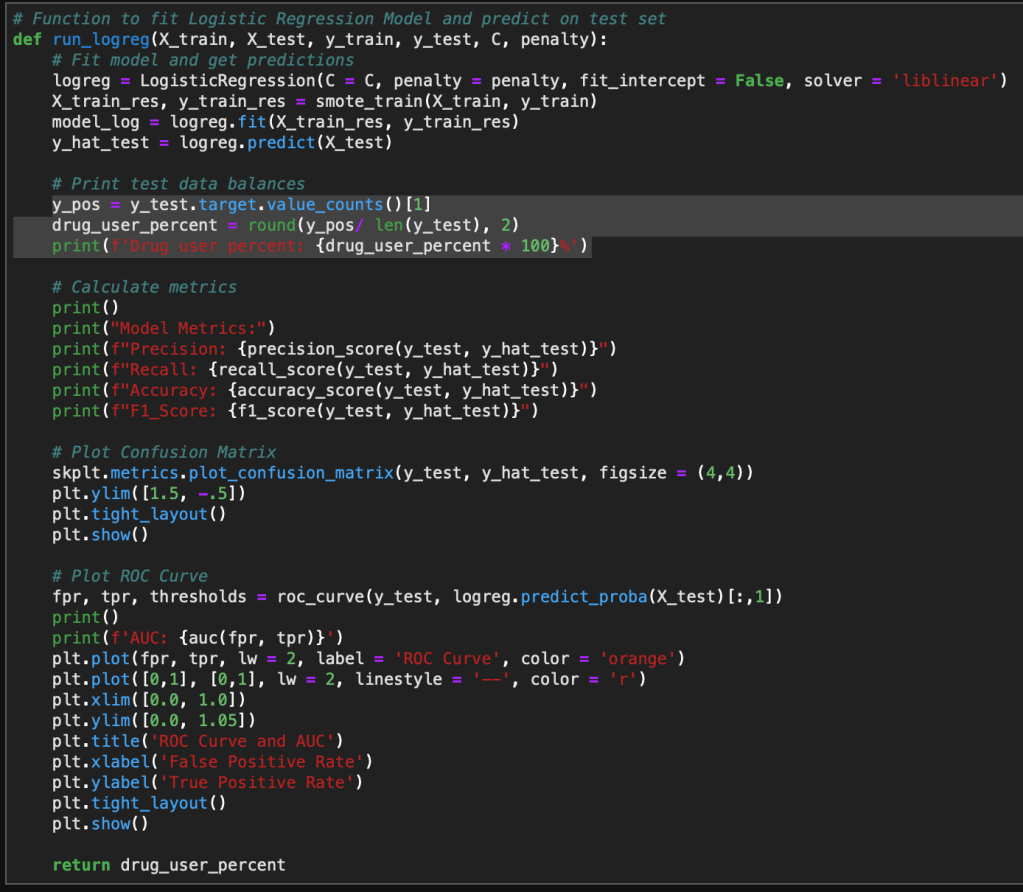
Finally, one last helper function. This is the function that actually fits the Logistic Regression model and creates output metrics and visualizations. This model takes in the train/test split data and the optimized hyperparameters C and Penalty type. The function when applied will create visualizations for the confusion matrix and ROC Curve. It also outputs the test sample’s class balance, which helps to inform how the test data is distributed.
Fitting the Model
Finally, it is time to fit all of the models and view the results. I wrote one last function which combines all of the above functions into one simple function that can be applied to a single DataFrame.
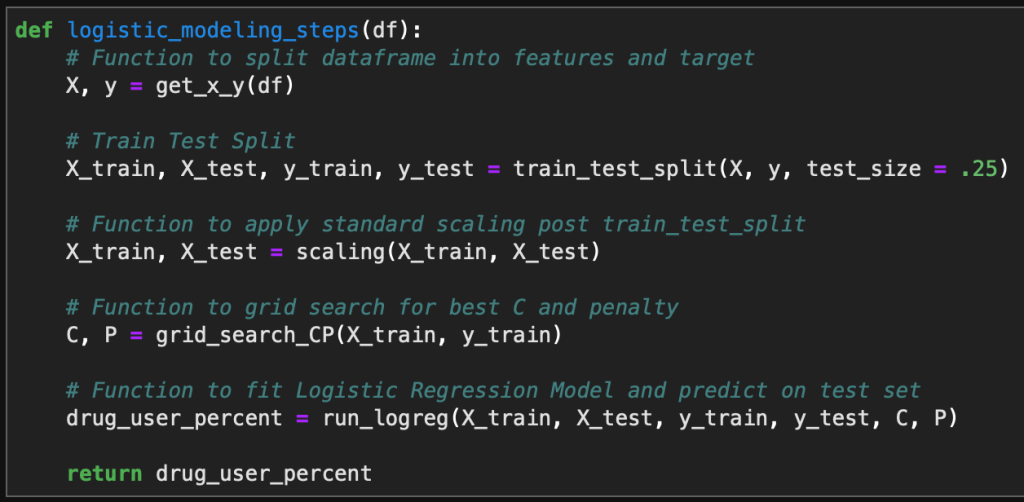
This function is then applied to each DataFrame in my previously created dictionary with a for loop to generate all of the necessary model results and visualizations.
Results
As there were 17 different drugs in question, I will only highlight a few of the results below. The Logistic Regression model performed well in most cases, although those with extremely unbalanced datasets performed slightly worse despite the use of SMOTE to balance the training sets.
Alcohol
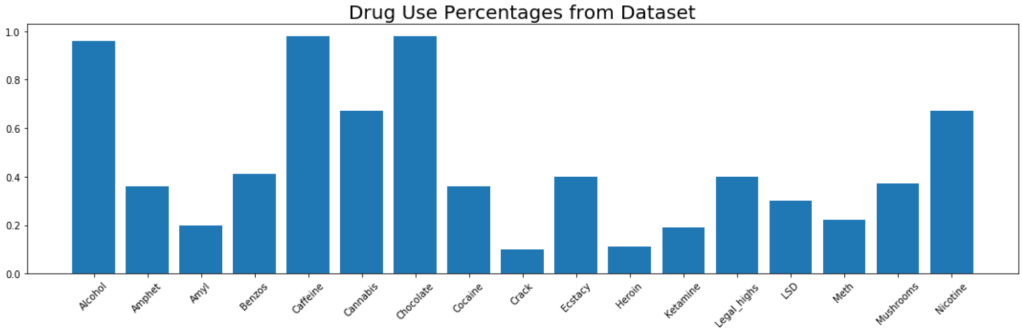
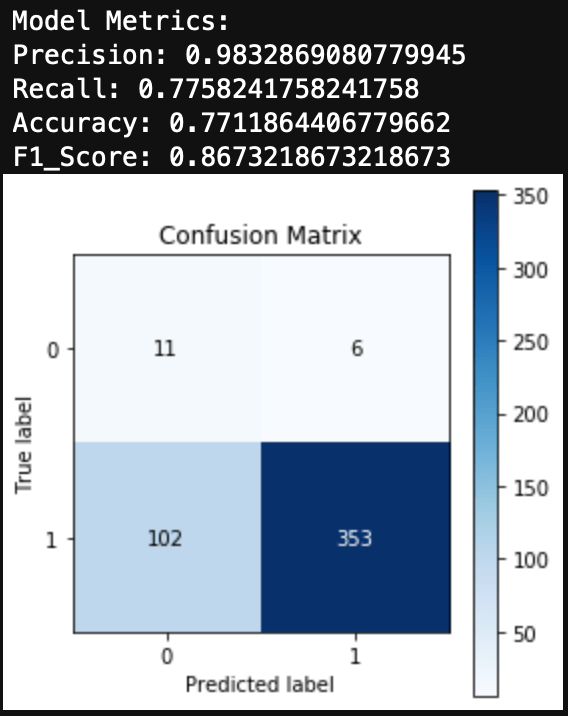
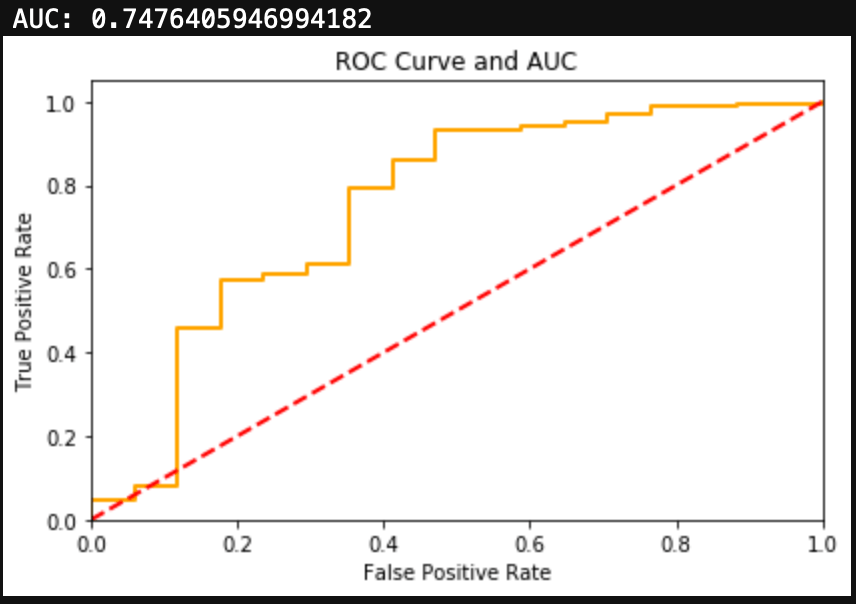
Alcohol had an extremely unbalanced dataset. You can see that 96% of the test group had used alcohol. Alcohol did produce a large number of false negatives, however the F1 Score and AUC metrics signaled that this was a decent model.
Cannabis
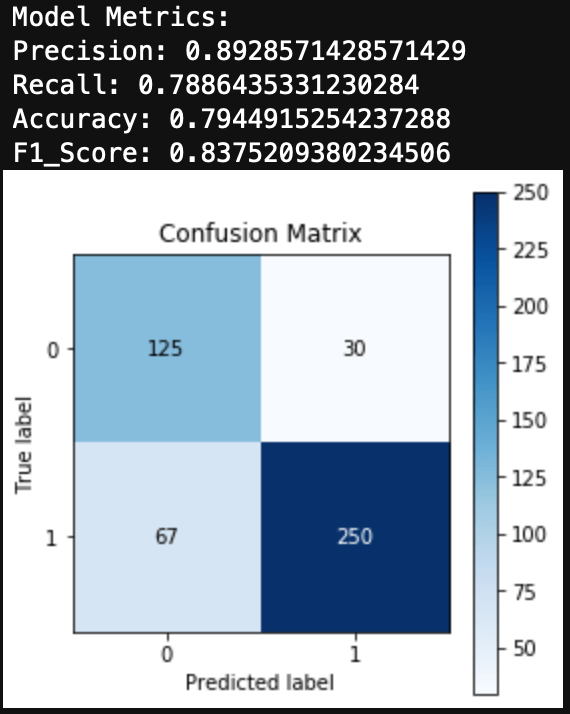
Cannabis had a more balanced dataset than alcohol, with 67% of the test group having used the drug. The Logistic Regression for Cannabis use was able to generate both a high F1 Score and high AUC.
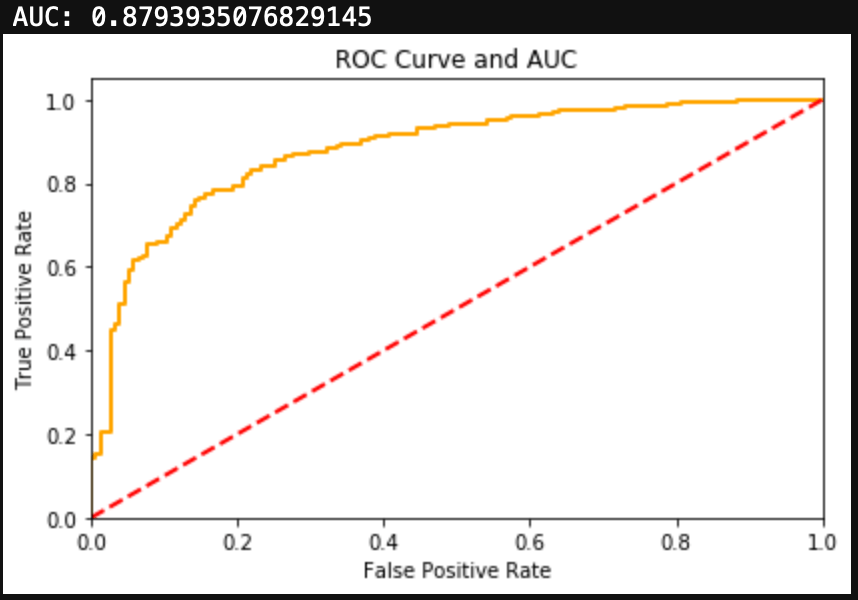
Nicotine
Nicotine also had a more balanced dataset than alcohol, with 67% of the test group having used Nicotine. Similarly to Cannabis, the Logistic Regression model for Nicotine was able to produce both a high F1 Score and a high AUC.
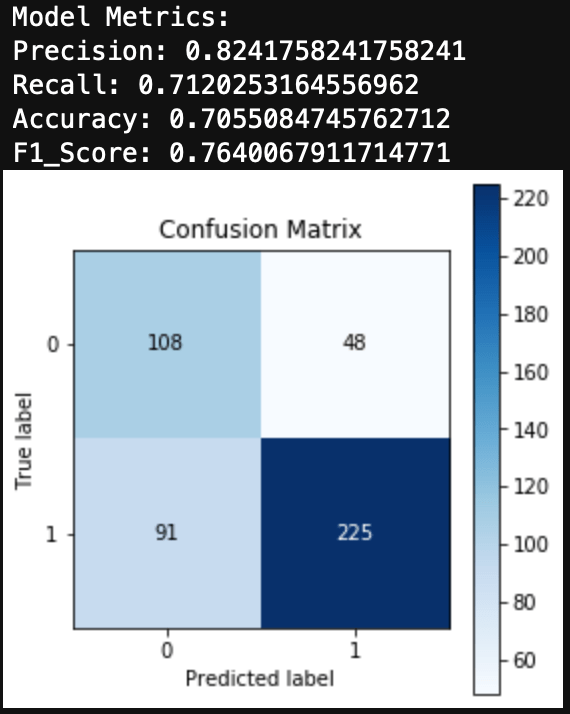
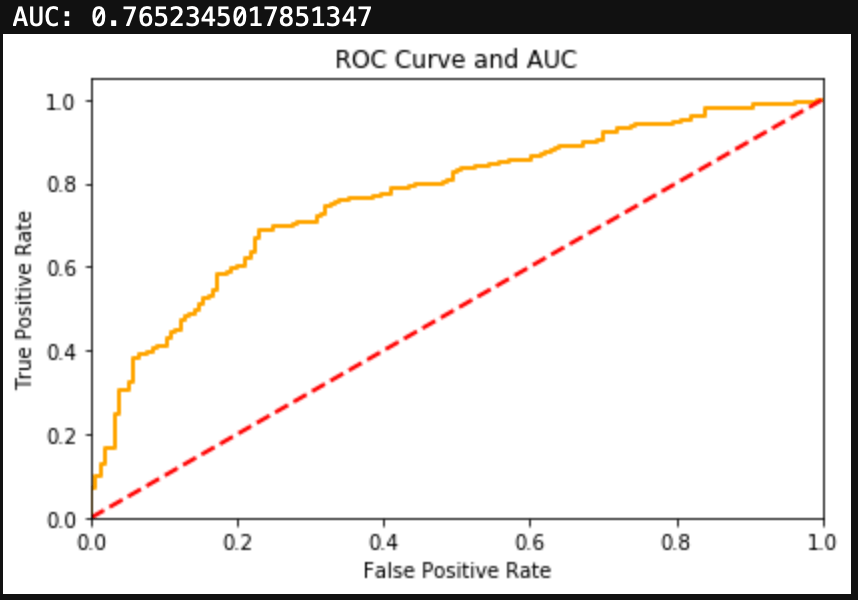
Meth
Finally, I’ll look at a drug that has an unbalanced dataset in the other direction. Obviously not a ton of people use Meth, although more than I imagined, with 24% of the test group having used Meth before. The Logistic Regression for Meth use produced a fair amount of false positives. Additionally the metrics and F1 Score are fairly low. The ROC Curve and AUC show decent results, but in the case of an unbalanced dataset, I would trust F1 Score over AUC.
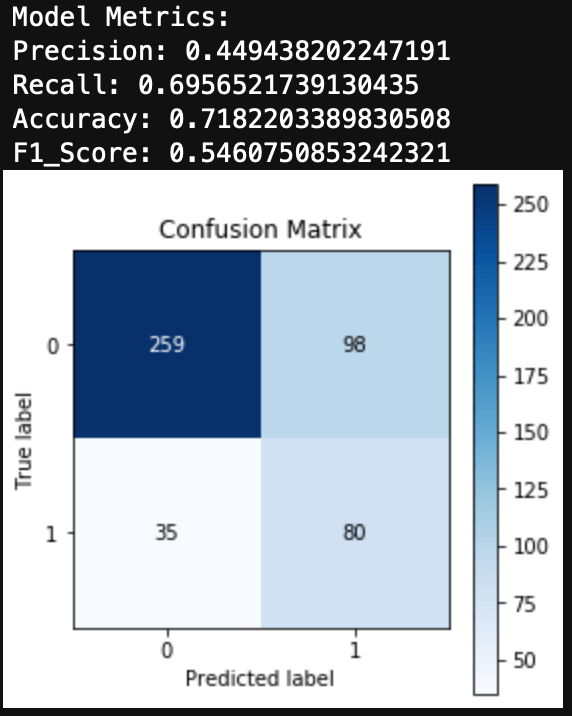
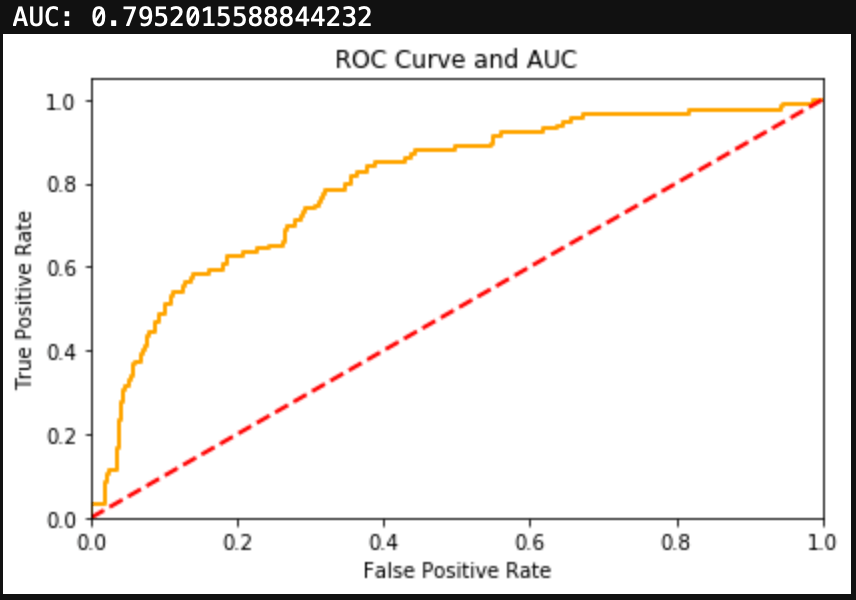
Conclusions
I was able to fit a Logistic Regression model to each of the drug use DataFrames, however for some of the drugs, Logistic Regression may not be the best choice classifier model. Since a lot of the datasets are unbalanced, this did cause some issues with the metrics.
Overall, the results were very good and could help to inform us about an individual’s drug use given information about their demographic traits and personality traits.
Just for Curiosity
Here is a bar chart of drug use percentage for all 1885 people in the dataset.